JavaScript 키워드 비동기 프로그래밍
🤔 왜 알아보고 싶었는가?
프론트엔드 코드 작업을 하면서 땔 수 없는 것이 바로 비동기 프로그래밍이다.
단순하게 서버에서 데이터를 받아오는 작업만 생각해도 비동기 프로그래밍이다.
하지만 이 비동기 프로그래밍을 내가 잘 알고 사용하는가 생각해보면 아닌 것 같다.
그래서 이번 기회에 비동기 프로그래밍과 이와 관련된 promise, async/await 와 같은 내용을 알아보려고 한다.
⚙️ 비동기 프로그래밍은 어떻게 동작하는 것인가?
앞서 실행 컨텍스트에서 어떠한 함수가 실행되면 실행 컨텍스트 스택(콜 스택) 에 하나씩 쌓이고 이것이 순차적으로 제거되면서 동작된다는 것을 알 수 있었다.
여기서 생기는 문제가 있는데 자바스크립트 엔진의 경우는 하나의 실행 컨텍스트 스택을 가진다.
이 말은 한 번에 하나의 일만 처리할 수 있는 것이다.
실행 컨텍스트의 최상위 요소인 실행 중인 실행 컨텍스트를 제외한 나머지 실행 컨텍스트들은 모두 대기중인 상태로 존재한다.
이를 다른 말로 표현하면 ’자바스크립트 엔진은 싱글 스레드 방식으로 동작한다.’
그런데 아래와 같은 코드를 생각해보자
function foo() {
console.log('foo');
}
function bar() {
console.log('bar');
}
setTimeout(foo, 3 * 1000);
bar();결과가 어떻게 나오는지 비동기 프로그래밍을 경험한 사람들은 알 수 있다.
bar가 먼저 출력되고 foo가 출력된다.
이러한 동작은 어떻게 동작할까? 단순하게 생각하면 실행 컨텍스트 스택에는 foo가 들어갈 것이고 해당 실행 컨텍스트가 마무리되야 bar가 동작할 것인데 신기하다. setTimeout이 마법인걸까?
보통 이러한 비동기 처리는 타이머 함수인 setTimeout, setInterval, HTTP 요청, 이벤트 핸들러 등에서 일어나고, 이러한 깜찍한 친구들은 이벤트 루프와 태스트 큐라는 것과 관계가 있다.
🎡 이벤트 루프와 테스크 큐
자바스크립트는 싱글 스레드 동작이 맞다.
하지만 브라우저는 다르다. 우리가 동시에 일어나는 것 처럼 느껴지는 것들은 브라우저에서 도움을 주는 것이다.
우리가 알아볼 이벤트 루프와 테스크 큐라는 친구들도 브라우저에서 지원해주는 기능인 것이다.
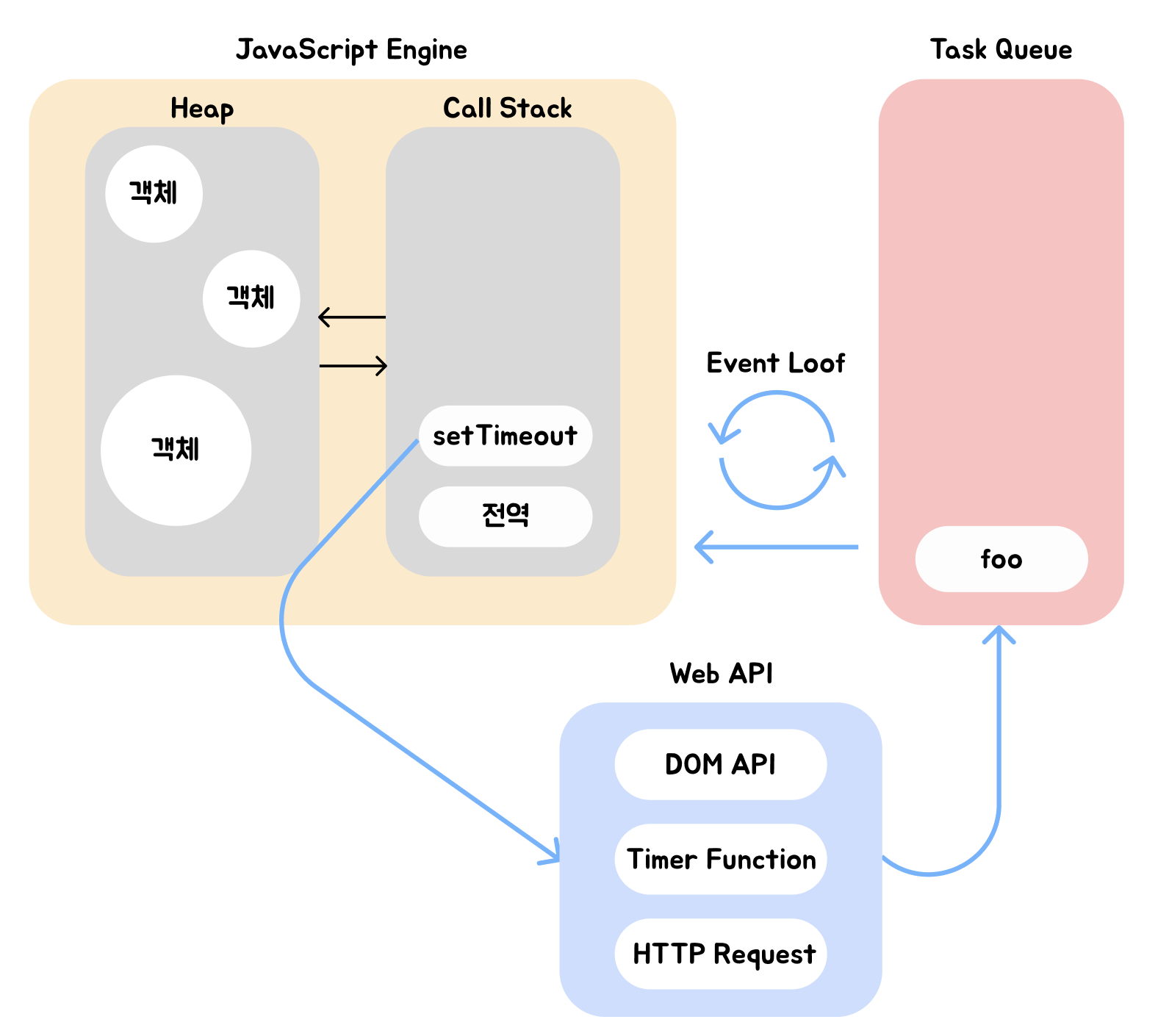
위 그림은 브라우저 환경을 대략적으로 표시한 그림이다.
일단 용어에 대해서 조금 알아보자
-
Call Stack: 생성된 실행 컨텍스트가 추가되고 제거되는 스택 자료구조인 실행 컨텍스트 스택을 말한다.
-
Heap: 객체가 저장되는 메모리 공간이다. Call Stack의 요소인 실행 컨텍스트는 Heap에 저장된 객체를 참조한다.
-
Task Queue(Event Queue, Callback Queue): 비동기 함수의 콜백 함수 또는 이벤트 핸들러가 일시적으로 보관되는 장소이다. Task Queue와는 별개로 프로미스의 후속 처리 메서드의 콜백 함수가 일시적으로 보관되는 Micro Task Queue가 존재하는데 이는 후에 더 알아본다.
-
Event Loop: Call Stack에 현재 실행 중인 실행 컨텍스트가 있는지, 그리고 Task Queue에 대기 중인 함수가 있는지 반복해서 확인한다. 만약 Call Stack이 비어있고 Task Queue에 대기 중인 함수가 있다면 Event Loop는 순차적으로 Task Queue에 대기 중인 함수를 Call Stack으로 이동시킨다.
그러면 위에서 알아본 샘플 코드가 어떻게 동작한 것인지 한 번 알아본다.
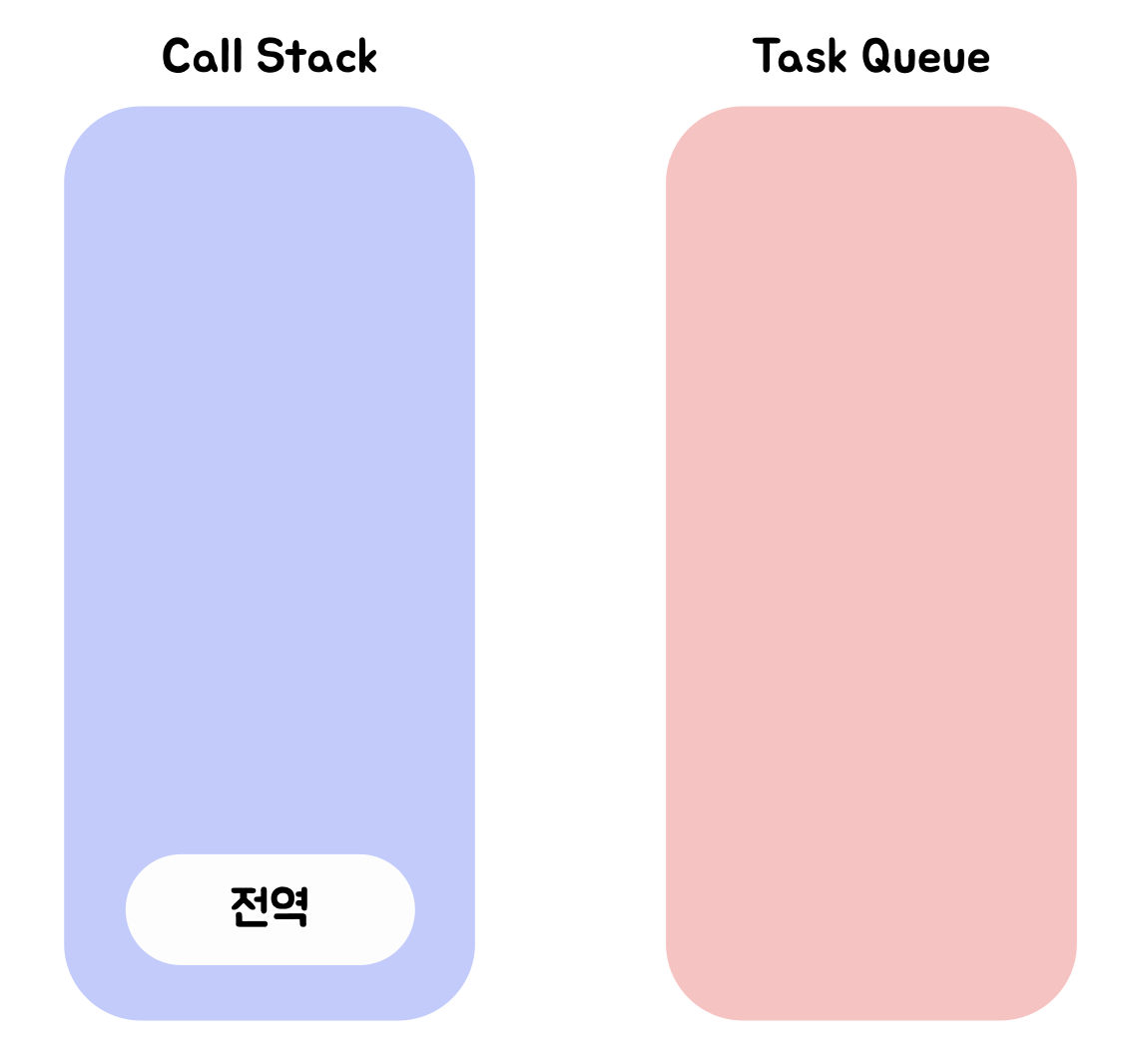
- 전역 코드 평가 이후 전역 실행 컨텍스트가 생성되고 Call Stack에 푸쉬된다.
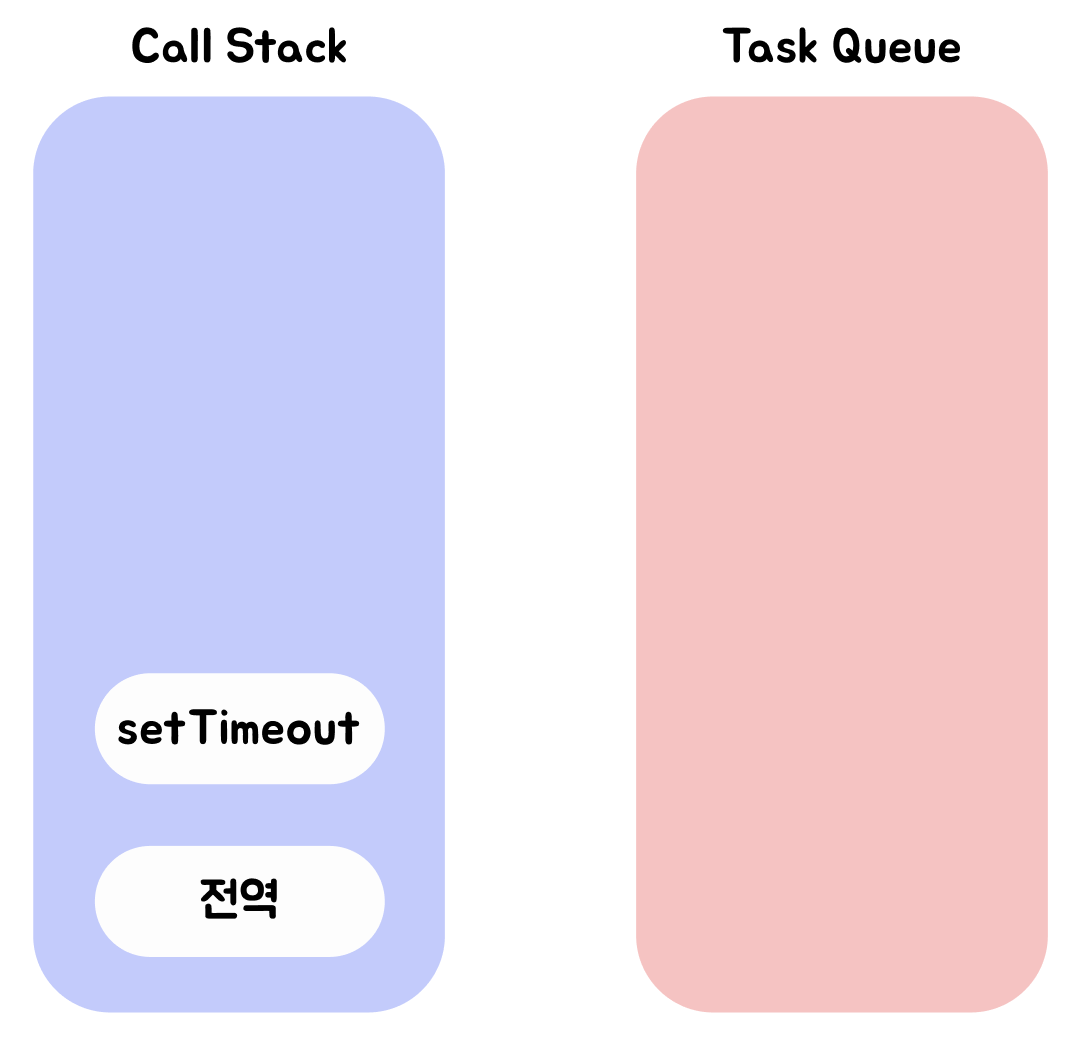
-
실행되면서 setTimeout 함수가 호출된다. 이때 setTimeout 함수의 함수 실행 컨텍스트가 생성되고 Call Stack에 푸쉬되어 현재 실행 중인 실행 컨텍스트가 된다. 이때 브라우저의 Web API인 타이머 함수도 함수이므로 실행 컨텍스트를 생성한다.
-
setTimeout 함수가 실행되면 콜백 함수를 호출 스케줄링하고 종료되어 Call Stack에서 팝된다. 이때 타이머 설정과 타이머가 완료되면 콜백 함수를 Task Queue에 푸쉬하는 호출 스케줄링은 브라우저의 역할이다.
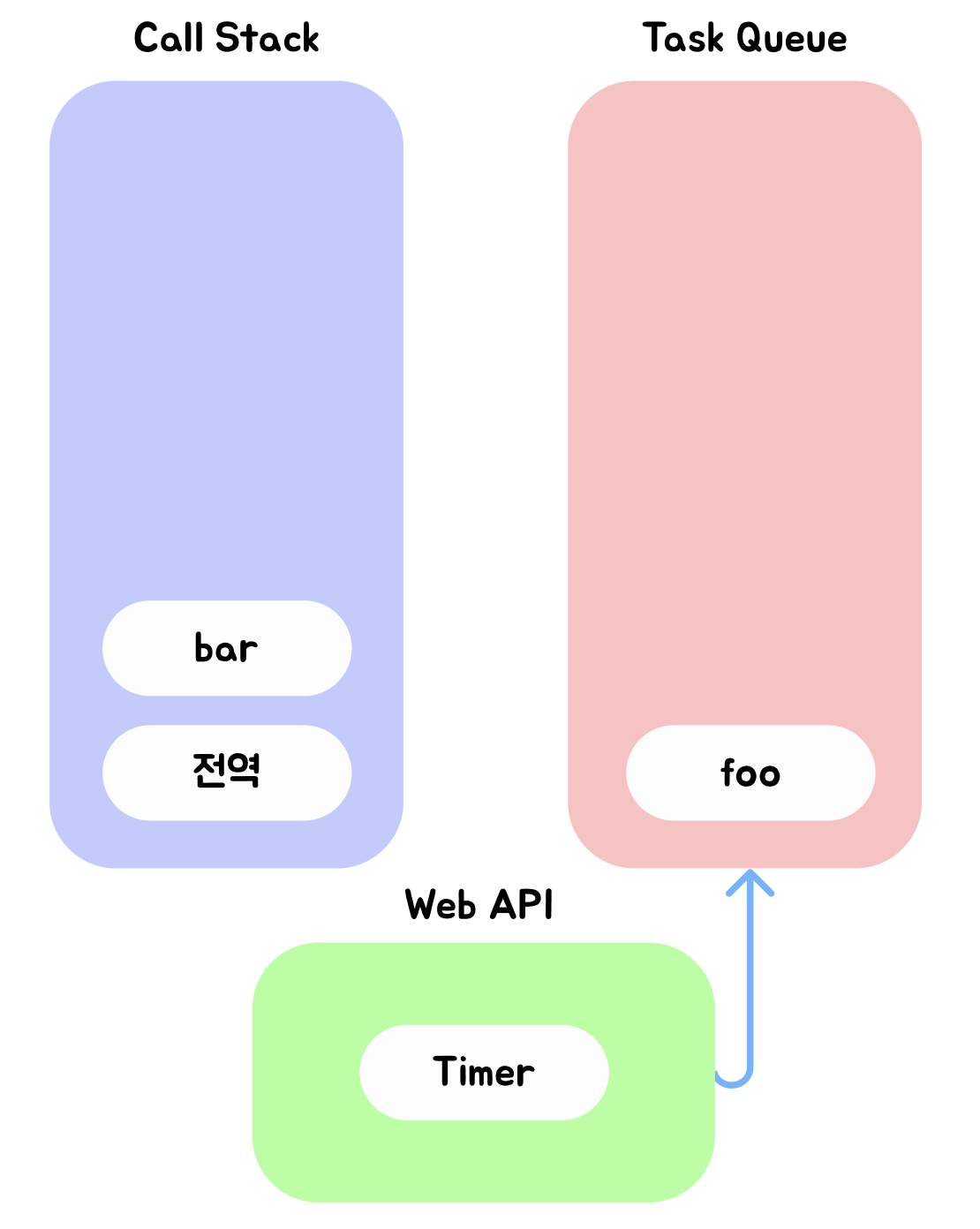
- 여기서는 브라우저 측면과 자바스크립트 엔진 측면을 따로 봐야한다.
- 브라우저는 타이머를 설정하고 타이머의 만료를 기다린다. 이후 타이머가 만료되면 콜백 함수 foo가 Task Queue에 푸쉬된다.
- 자바스크립트 엔진의 경우 bar 함수가 호출되어 bar 함수의 실행 컨텍스트가 생성되고 Call Stack에 푸쉬되어 현재 실행되는 실행 컨텍스트가 된다. 이후 함수가 종료되면 Call Stack에서 팝된다.
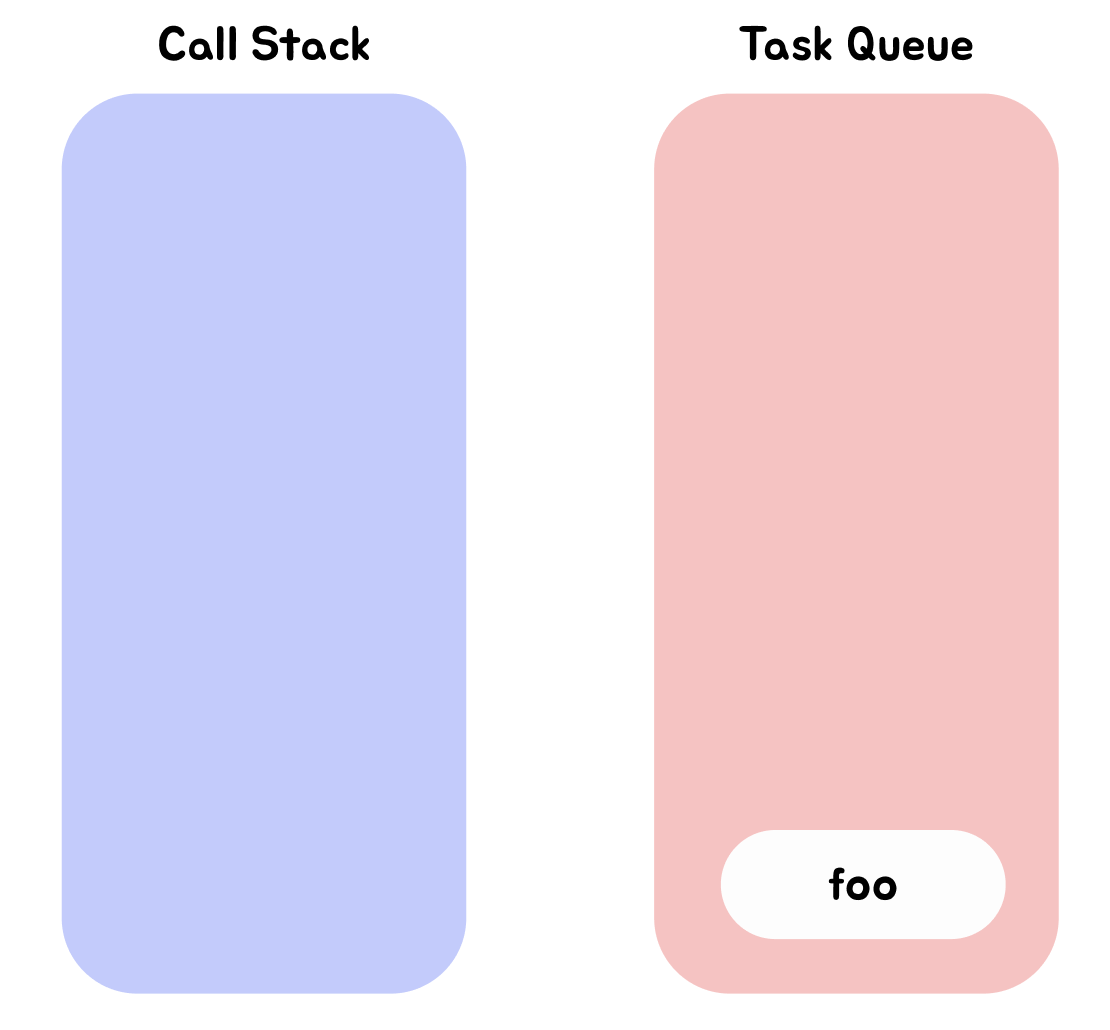
- 전역 코드 실행이 종료되고 전역 실행 컨텍스트가 Call Stack에서 팝된다. 이제 Call Stack에는 아무런 실행 컨텍스트가 존재하지 않는다.
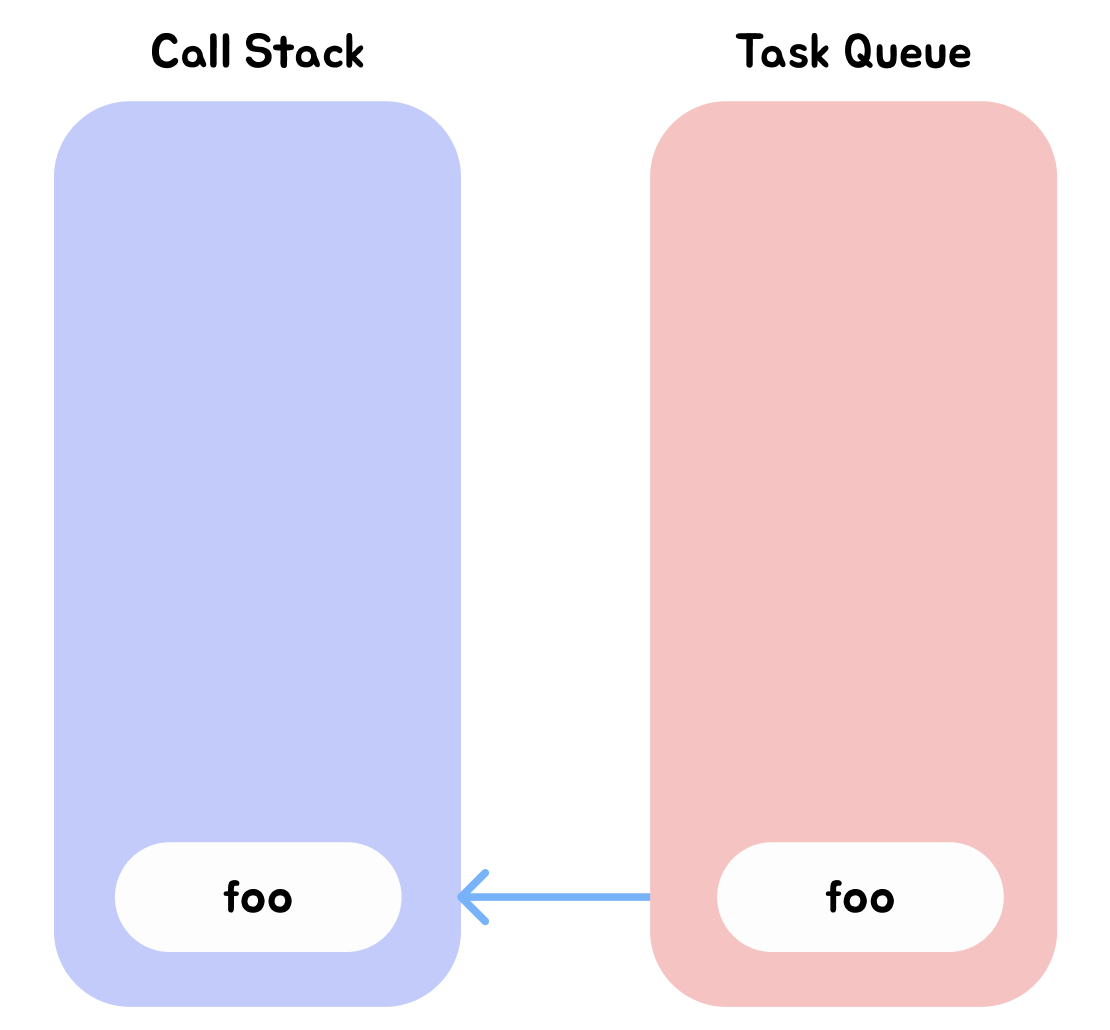
-
Event Loop에 의해 Call Stack이 비어있다는 것을 확인하고 Task Queue에서 대기 중인 콜백 함수 foo가 Event Loop에 의해 Call Stack에 푸쉬된다.
-
이후 foo 함수의 실행 컨텍스트가 생성되고 Call Stack에 푸쉬되어 현재 실행중인 실행 컨텍스트가 된다.
-
이후 실행이 완료되면 Call Stack에서 팝된다.
다음과 같은 흐름으로 진행이 되어서 우리가 생각했던 그 결과가 출력이 된 것이다.
자바스크립트는 싱글 스레드 방식으로 동작한다는 말을 오해할 수 있다. 이 말은 브라우저가 싱글 스레드 방식으로 동작한다는 것이 아니다. 그 안에 내장된 자바스크립트 엔진이 싱글 스레드인 것이다.
브라우저는 자바스크립트 엔진 외에도 Web API와 렌더링 엔진이 제공된다.
Web API는 ECMAScript 사양에 정의된 함수가 아니라 브라우저에서 제공하는 API이다. DOM API와 타이머 함수, HTTP 요청(Ajax)와 같은 비동기 처리를 포함한다.
👨🏻🔧 Ajax
우리가 비동기 함수를 사용하는 것 중에서 가장 많이 사용하는 것이 무엇일까?
아마? 당연하게도? HTTP 요청일 것이다. 우리의 이러한 요청을 들어주는 것이 바로 Ajax 이다.
Ajax는 Asynchronous JavaScript and XML 의 약자이다.
Ajax란 자바스크립트를 사용하여 브라우저가 서버에게 비동기 방식으로 데이터를 요청하고, 서버가 응답한 데이터를 수신하여 웹 페이지를 동적으로 갱신하는 프로그래밍 방식을 말한다.
이러한 Ajax는 브라우저에서 제공하는 Web API인 XMLHttpRequest 객체를 기반으로 동작한다.
그러면 왜 이런 프로그래밍 방식이 성장하게 되었을까?
이를 알아보려면 이전의 방식을 알아봐야 한다. 이전 방식은 어떨까?
이전 방식은 완전한 HTML 문서를 서버로 받아서 웹 페이지 전체를 처음부터 다시 렌더링 하는 방식을 사용했다. 이러한 방식은 문제가 있는데
- 차이가 거의 없는 경우에도 완전한 HTML을 서버로부터 매번 다시 받아오기 때문에 불필요한 데이터 통신이 일어난다.
- 변경이 필요 없는 부분까지도 처음부터 다시 렌더링 한다. 이로 인한 화면 깜빡임이 발생한다.
- 클라이언트와 서버와의 통신이 동기 방식이기 때문에 응답이 올 때까지 블로킹 된다.
그러면 Ajax가 나온 이후에는 어떨까?
웹 페이지 변경에 필요한 데이터만 비동기 방식으로 전송받아 웹 페이지를 부분적으로만 렌더링이 가능해졌다. 이로 인한 장점은 무엇일까?
- 변경할 부분을 갱신하는데 필요한 데이터만 서버로부터 전송받기 때문에 불필요한 데이터 통신이 발생하지 않는다.
- 변경할 필요가 없는 부분은 다시 렌더링하지 않는다. 이로 인해서 깜빡이는 현상이 없다.
- 클라이언트와 서버와의 통신이 비동기 방식이기 때문에 블로킹이 발생하지 않는다.
우리가 요즘 브라우저에서 웹 페이지를 보는 방식과 유사하다.
본인이 글을 쓴 이유는 비동기 프로그래밍 방식을 알아보려 했던 것이니 Ajax에 관한 내용은 여기까지 적도록 한다. 혹시나 궁금한 내용이 있으면 XMLHttpRequest 객체를 학습해보면 된다.
🤝🏻 프로미스
자바스크립트는 기존에 비동기 처리를 위해서 콜백 함수를 사용하는 패턴을 사용하였다.
하지만 이 패턴의 경우에는 콜백 헬로 인한 가독성이 문제이고, 비동기 처리 중 발생한 에러의 처리가 힘들며, 여러 개의 비동기를 한 번에 처리하기도 힘들었다.
이를 위해 탄생한게 여러분이 알고 있는 프로미스이다.
프로미스는 ES6에서 도입이 되었고 콜백 패턴이 가지고 있는 단점을 보완하며 비동기 처리 시점을 명확하게 표현할 수 있다.
👶🏻 프로미스의 생성
프로미스는 Promise 생성자 함수를 new 연산자와 함께 호출하면 된다.
이때 생성자 함수에 인수로 비동기 처리를 수행할 콜백 함수를 전달해주는데 이 콜백 함수는 resolve와 reject 함수를 인수로 전달 받는다.
대략 아래와 같은 구조로 보면 된다.
const promise = new Promise((resolve, reject) => {
// Promise 함수의 콜백 함수 내부에서 비동기 처리를 수행한다.
if(/* 비동기 처리 성공! */){
resolve('success');
} else { /* 비동기 처리 실패... */
reject('fail');
}
});이렇게 보니 조금은 애매하다면 앞서 잠깐 언급했던 XMLHttpRequest를 사용한 예시를 보면 아래와 같다.
const promiseGet = (url) => {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.send();
xhr.onload = () => {
if (xhr.status === 200) resolve(JSON.parse(xhr.response));
else reject(new Error(xhr.status));
};
});
};위와 같이 Promise 객체 내부에서 비동기 처리를 진행하고 성공 시와 실패 시를 나눠서 resolve 또는 reject를 실행하는 구조이다.
위 코드에서는 지금 Promise 객체를 반환한다. 내부적으로는 어떻게 동작하는지 알겠는데 저 객체는 어떻게 이루어진 객체일까?
Promise 객체는 비동기 처리 상태와 결과를 관리하는 객체이다.
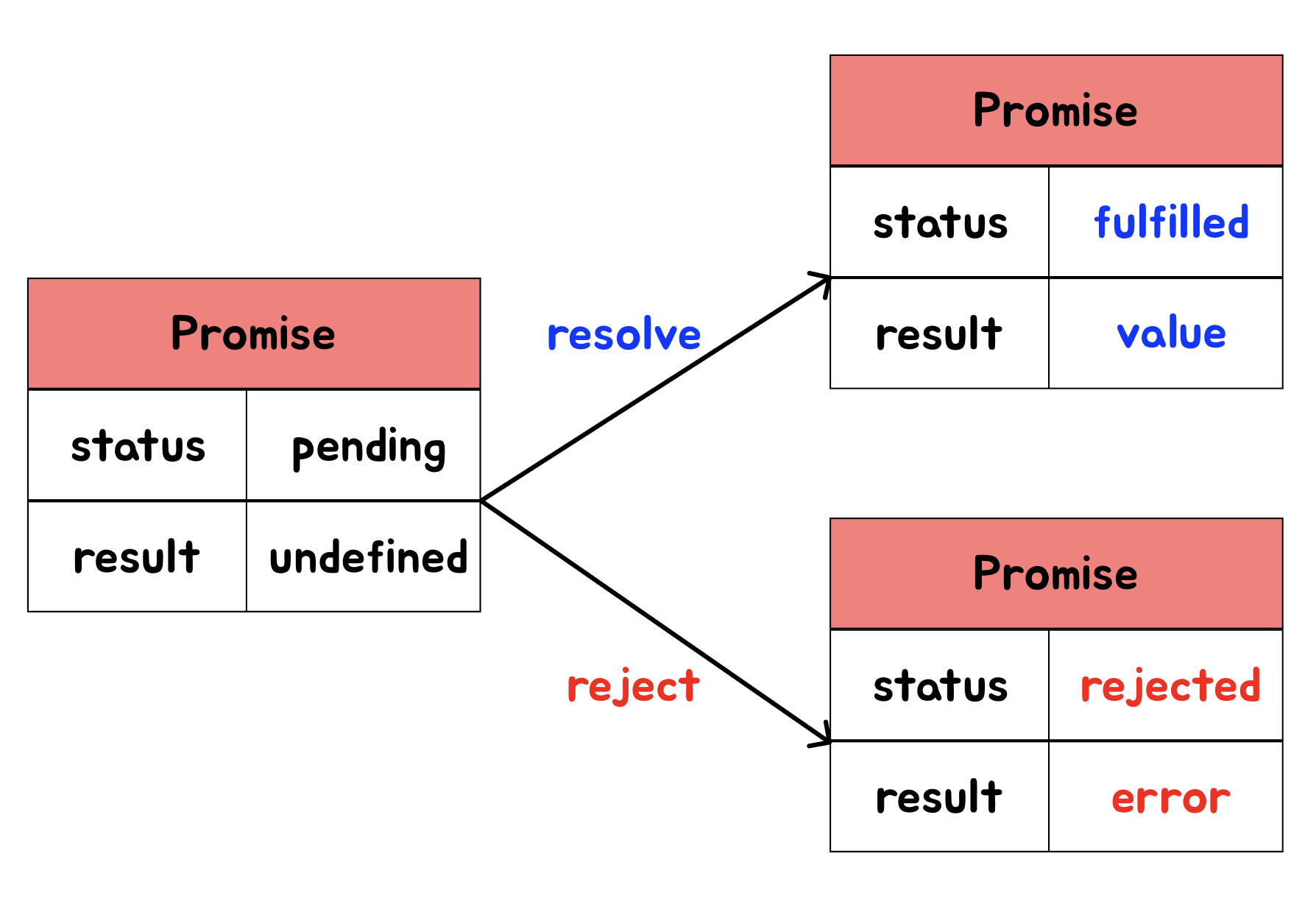
위 그림은 프로미스의 비동기 처리 전, 성공시, 실패시 상태를 나타내는 그림이다.
비동기 처리 전을 먼저 보면 상태는 pending, 결과는 아직 나오지 않았기 때문에 undefined 이다.
여기서 상태를 바꾸는 분기점이 바로 resolve 함수, reject 함수 이다.
resolve 함수를 호출하면 상태는 fulfilled, 결과에는 인자로 넣어준 value 값이 된다.
reject의 경우에는 상태는 rejected, 결과에는 인자로 넣어준 error가 들어간다.
한 번 실제 상황을 봐보면 이해하기 쉽다.
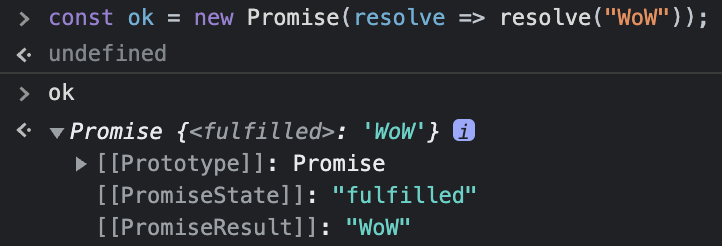
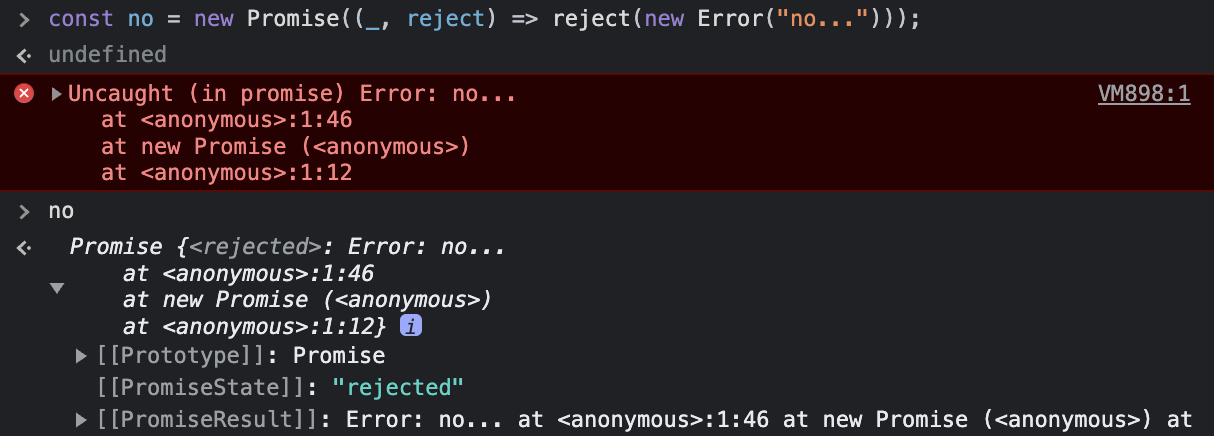
앞서 그림으로 살펴보았던 내용들이 그대로 있는 것을 볼 수 있다.
🤔 콜백을 보완했다고 하는데 어떻게?
앞서 설명했던 것 처럼 프로미스는 콜백 패턴을 보완했다고 했다. 하나씩 살펴보면서 어떻게 보완이 된 것인지 살펴보자
🤬 에러 처리
catch 메서드로 에러를 핸들링 한다.
catch 메서드는 하나의 콜백 함수를 인수로 전달받고 프로미스가 rejected 상태인 경우에만 호출이 된다. 아래 코드를 보면 어떻게 에러 처리를 하는지 볼 수 있다.
new Promise((_, reject) => reject(new Error('no...'))).catch((e) => console.log(e));대부분의 사람들이 주로 쓰는 then 메서드를 이용해서 처리할 수 있다.
new Promise((_, reject) => reject(new Error('no...'))).then(undefined, (e) => console.log(e));👨👩👧👦 다중 처리
Promise.all 메서드를 통해서 여러 개의 비동기 처리를 모두 병렬처리를 할 수 있다.
Promise.all 메서드는 인수로 전달받은 배열의 모든 프로미스가 모두 fulfilled 상태가 되면 종료된다. 따라서 모든 처리에 걸리는 시간은 가장 늦게 fulfilled 상태가 되는 비동기 처리보다 조금 더 길다.
모든 프로미스가 fulfilled 상태가 되면 resolve된 처리 결과를 배열에 저장해 새로운 프로미스를 반환한다. 이때 처리 순서가 보장이 된다.
만약 하나라도 reject가 된 경우에는 다른 프로미스들의 fulfilled를 기다리지 않고 즉시 종료한다.
const requestData1 = () => new Promise((resolve) => setTimeout(() => resolve(1), 3000));
const requestData2 = () => new Promise((resolve) => setTimeout(() => resolve(2), 2000));
const requestData3 = () => new Promise((resolve) => setTimeout(() => resolve(3), 1000));
// 이 경우에는 가장 늦게 끝나는 requestData1 에 맞춰서 3초 + 알파가 걸린다.
Promise.all([requestData1(), requestData2(), requestData3()])
.then(console.log) // [1, 2, 3]
.catch(console.error);⛓ 프로미스 체이닝
프로미스의 경우에는 콜백 헬을 해결하기 위해서 나왔다고 했다.
프로미스의 경우에는 그래서 then, catch, finally 같은 후속 처리 메서드를 통해서 콜백 헬을 해결한다.
근데 해결이 된걸까..?
일단 간단한 예제를 보고 확인해보자.
const url = 'https://test.hello.com';
promiseGet(`${url}/posts/1`)
.then(({ userId }) => promiseGet(`${url}/users/${userId}`))
.then((userInfo) => console.log(userInfo))
.catch((err) => console.error(err));위 코드는 then -> then -> catch 순서로 후속 처리 메서드를 사용하면서 프로미스를 처리하였다.
이처럼 후속 처리 메서드는 언제나 프로미스를 반환한다는 사실을 통해 연속적으로 호출할 수 있다. 이를 프로미스 체이닝이라 한다.
이처럼 프로미스는 프로미스 체이닝을 통해 비동기 처리 결과를 전달받아 후속 처리를 하므로 비동기 처리를 위한 콜백 패턴에서 발생하던 콜백 헬은 지웠다… 라고 할 수 있다.
하지만 프로미스도 결국 콜백 패턴을 사용하는 모양새로 이는 가독성이 좋지 않다.
이를 해결한 것이 바로 ES8에 등장한 async/await 이다. 이는 뒤에서 더 살펴보자
⏱ 마이크로태스크 큐
앞 전에 플래그를 새워둔 마이크로태스크 큐 이다. 코드를 통해서 이상한 점을 살펴보자
setTimeout(() => console.log(1), 0);
Promise.resolve()
.then(() => console.log(2))
.then(() => console.log(3));과연 위 코드는 어떻게 동작할까?
두구두구두구 정답은 ~
2 -> 3 -> 1 이다!
왜일까? 앞서 살펴본 내용들만 생각하면 Task Queue에는 setTimeout, Promise 순으로 들어가서 순서대로 처리가 되어 1 -> 2 -> 3 일 것 같은데?
이는 프로미스의 후속 처리 메서드의 콜백 함수들은 Task Queue가 아니라 마이크로태스크 큐(Microtask Queue) 에 저장되기 때문이다.
Microtask Queue는 TaskQueue와는 별도이다.
Microtask Queue는 프로미스의 후속 처리 메서드의 콜백 함수가 일시 저장된다.
그 외에 비동기 함수의 콜백 함수나 이벤트 핸들러는 Task Queue에 일시 저장된다.
콜백 함수나 이벤트 핸들러를 일시 저장한다는 점에서 Task Queue와 동일하지만 Microtask Queue는 Task Queue보다 우선순위가 높다.
이말은 Event Loop는 Call Stack이 비면 먼저 Microtask Queue에서 대기중인 함수를 가져다가 실행한다.
🎁 fetch
마지막으로 알아볼 내용은 fetch이다. 사실상 우리가 가장 많이 쓰는 Web API다.
fetch 또한 XMLHttpRequest 객체와 마찬가지로 HTTP 요청 기능을 제공하는 클라이언트 사이드 Web API다.
하지만 다른 점이라면 사용법이 간단하고 프로미스를 지원한다는 것이다.
fetch 함수는 HTTP 응답을 나타내는 Response 객체를 래핑한 Promise 객체를 반환한다. 그렇기 때문에 우리는 then을 통해서 후속처리를 할 수 있는 것이다.
fetch('https://test.com')
.then(response => response.json())
.then(json => console.log(json());이 글에서는 fetch를 다 알아볼 예정은 아니고 주의사항만 알아보고 넘어갈 것이다.
fetch 함수가 반환하는 프로미스는 기본적으로 404나 500과 같은 HTTP 에러가 발생해도 에러를 reject 시키지 않고 불리언 타입의 ok 상태를 false로 설정한 Response 객체를 한다.
이 말은 오프라인등의 네트워크 장애나 CORS 에러에 의해 요청이 완료되지 못한 경우에만 프로미스를 reject 한다는 뜻이다.
따라서 fetch 함수를 사용할 때에는 다음과 같이 resolve한 불리언 타입의 ok 상태를 확인해서 명시적으로 에러를 처리해야 한다.
const errorUrl = 'https://error.com';
fetch(errorUrl)
.then(response => {
if(!response.ok)
throw new Error(response.statusText);
return response.json()
}
})
.then(todo => console.log(todo))
.catch(err => console.error(err));😃 다음에 이어질 내용
이번 한 편으로 비동기 관련 이야기를 모두 하려고 했으나 그것은 무리였다…
이번에 다루고자 했던 내용 중 빼먹은 것이 있는데 바로
언급만 하고 이야기는 1도 안했던 async/await 이다.
다음 편에서는 async/await 와 관련된 이야기를 조금 나눠보고자 한다.
이번에도 긴 글을 읽어주신 분이 있다면 너무 감사드리고, 수정할 내용이 있다고 하면 댓글 남겨주시면 감사드립니다. 🙇🏻♂️