깃의 서버 저장소 GitHub
😃 이번에 알아볼 내용은?
고민이 좀 있었다.
깃 위주로 해서 브랜치가 또 핵심 개념이니 브랜치를 학습할지 아니면 결국 올리는 공간인 GitHub 같은 서버 저장소를 학습할까 였다.
생각을 해보니 GitHub에 대해서 내가 많이 아는가 음… 모르겠다.
그래서 학습하기로 했다.
GitHub의 여러 내부 기능을 살피는 것이 아닌 원격 저장소 연결과 관리 위주로의 학습을 하기로 결정했고, 만일 GitHub의 기능을 살피러 오신 분이 계시다면 이 글은 그런 글은 아닐 것이라는 것을 미리 언급하고 시작해보겠다.
🖥 서버 저장소
서버 저장소는 다른 말로는 원격 저장소라고 한다.
서버 저장소는 로컬 저장소(레포지토리)를 복제한 복사본이라고 할 수 있다.
서버를 이용하면 장점이 무엇일까?
바로 다른 사람과의 공유와 협업이 편해진다는 부분일 것이다. 물론 본인의 컴퓨터가 뽀각 되어도 살아있다는 장점도 있겠지만 협업의 과정이 더 값질 것이다.
협업을 왜 할까?
이에 대한 답은 조금 쉽다. 단순하게 네이버, 카카오톡, MS 등의 프로그램이나 서비스를 생각해보자. 혼자서 만들 수 없는 규모이다. (물론 만들 수 있겠지만 그러면 천재가 아닐까?)
애초에 깃이란 것이 탄생한 것도 리눅스를 개발하는 과정에서 협업을 편하게 하기 위해서 탄생한 것으로 알고 있다.
서버 저장소는 이런 협업을 도와준다.
깃은 분산형 모델을 선택해 협업을 도와준다.
분산형 모델은 인터넷에 연결이 되지 않아도 개발 작업을 이어나갈 수 있도록 도와주는데 한 번 간단한 예시를 떠올려보자.
우리는 사무실에서 개발을 진행한다고 가정해보자. 오늘은 이른 퇴근을 해야한다. 하지만 일을 다 못했다. (가정이다. 실제로 이러면 짤리겠죠?)
이때 우리는 현 시점까지의 개발 코드를 서버에 올리고 집에 돌아와서 해당 코드를 본인 컴퓨터에 동기화 한 후 작업을 이어갈 수 있다.
다음 날 신입이 갑작스래 들어왔 가정해보자. 이 신입에게는 현 시점까지의 코드를 서버 주소를 통해 제공할 수 있다. 편하다.
이 과정에서 우리는 올리는 과정, 내려받는 과정을 제외하고는 서버에 원격적으로 접속해서 작업을 하지 않아도 된다. 이 부분이 깃의 분산형 모델의 예시이다.
깃은 분산된 저장소 여러개를 하나로 통합하고 최신 코드를 배포할 수 있도록 돕는다. 서버 저장소는 여러 컴퓨터에 동일한 깃 저장소를 복제하고, 작업한 결과물을 다시 서버로 통합하는 것이다.
🧭 GitHub를 이용해보자
우리는 깃 서버를 만들 수 있다. 하지만 꼭 그럴 필요는 없다.
깃 서버를 만들고 이용한다고 하면 추가 비용도 들 것이고 안정적인 서버 운영이 힘들 수 있다.
이러한 우리를 위해 편한 서비스가 존재하는데 바로 GitHub 이다.
GitHub는 대표적인 깃 호스팅 사이트이다. 모두 무료로 사용 가능하고 안정적으로 우리의 코드를 보관하고 공유할 수 있도록 도와준다.
대다수의 이 글을 읽는 사람들은 물론 이미 GitHub를 이용해보았겠지만 아에 처음 사용하는 사람 입장으로 생각해보자.
1. 우선 회원가입을 해보자!
https://github.com/ 으로 이동해서 회원가입을 하자!
회원 가입은 우 상단 Sign up을 통해서 진행하면 된다.
2. 서버 저장소를 만들자!
회원 가입이 완료되었으면 우 상단의 + 버튼 → New repository 라는 것을 눌러 여러분만의 서버 저장소를 만들 수 있다.
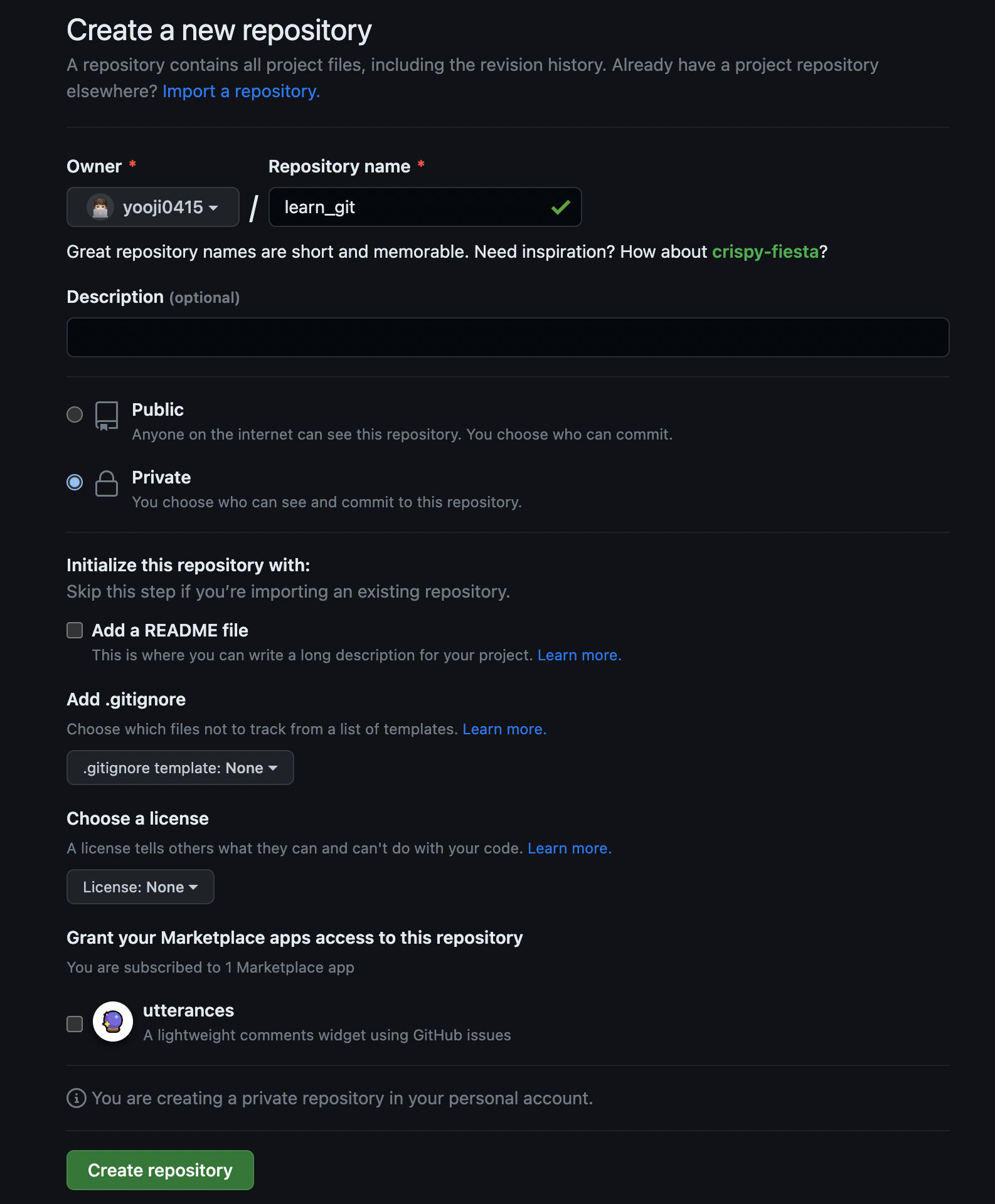
누르면 위와 같은 화면을 볼 수 있다.
Owner를 눌러 본인을 선택하고 옆에 name란에 본인이 원하는 이름을 적어주면 된다.
아래에 있는 Public과 Private는 말 그대로 이 저장소에 올리는 파일들이나 이 저장소 자체를 본인만 볼 것인지, 아니면 모두가 볼 수 있는지 선택하는 것으로 본인은 Private를 설정했다.
아래에 있는 Add a README file 체크박스는 새로 생성하는 서버 저장소에 기본적인 설명 파일을 만들 것인지를 결정하는 것으로 본인은 체크하지 않았다.
다 완료했으면 Create repository를 눌러서 생성해보자.
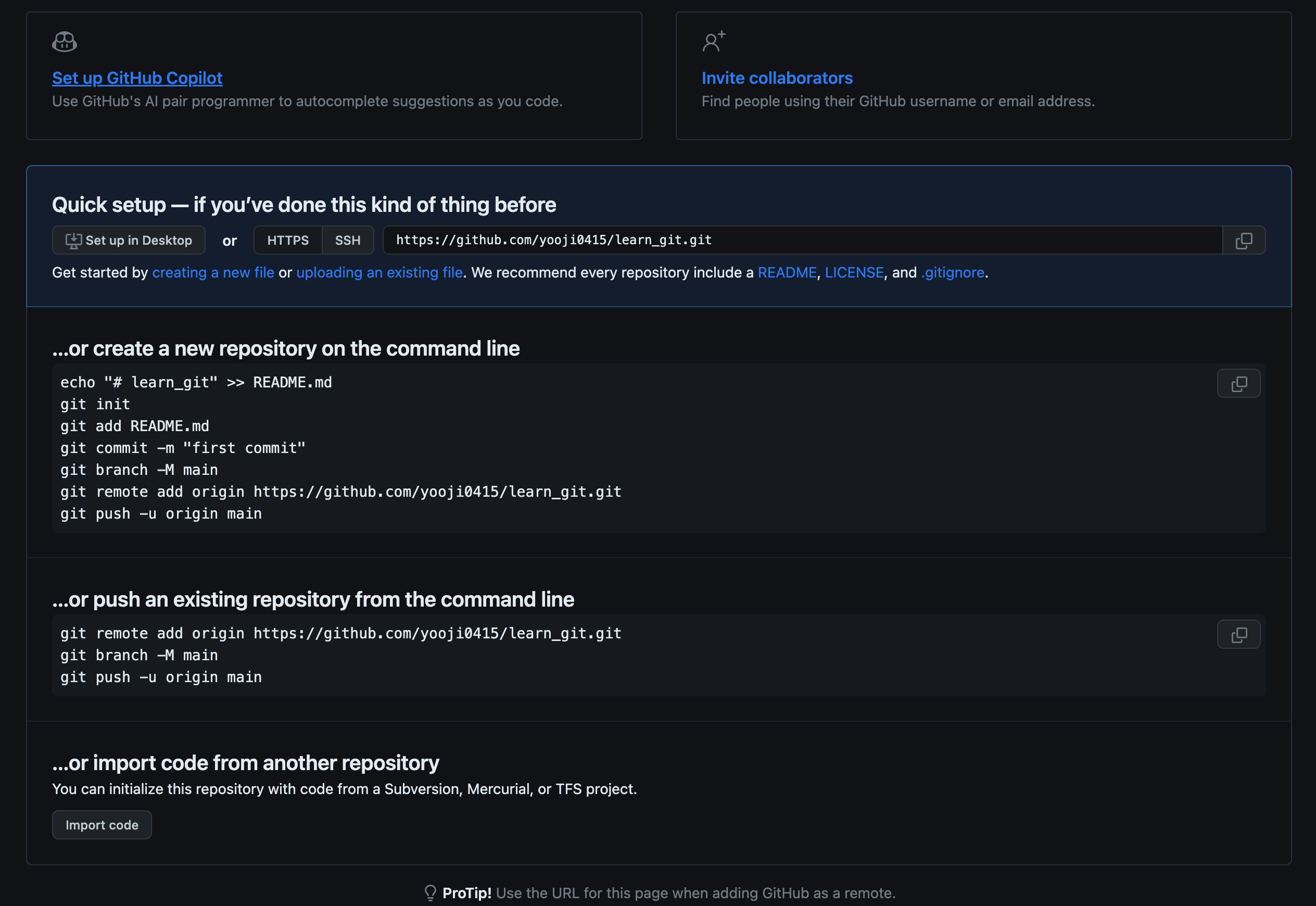
이런 화면이 보인다면 성공이다.
3. 서버 저장소와 연동해보자!
위 화면에서 알려주는 것은 연동 방법이다.
첫 번째는 새로운 로컬 저장소를 생성하고 원격 저장소를 연결하는 방법,
두 번째는 기존에 코드를 작성하던 깃 로컬 저장소를 연결하는 방법이다.
둘 중 하나를 선택해서 본인이 진행해도 좋고, 본인은 1번을 이용해서 진행했다.
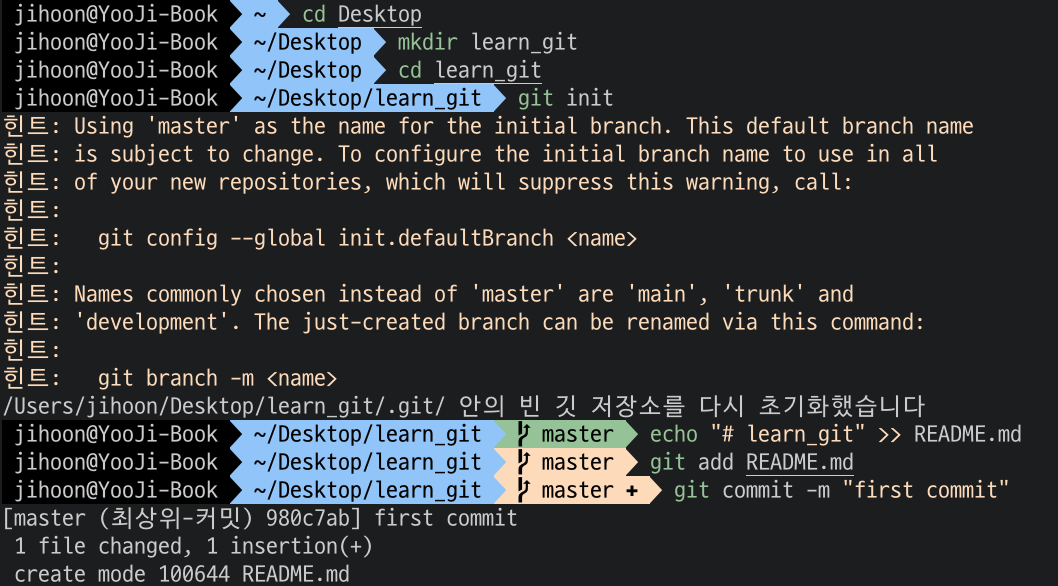
우선은 폴더를 생성하고 해당 폴더에 README.md 파일을 echo를 통해서 생성했다.
이후 해당 파일을 스테이지로 올린 후 commit을 했다.
여기까지는 이전까지 하던 방식과 비슷하다.
우리는 지금 서버 저장소와 연동을 하려고 하고 있다.
서버와 통신을 그러면 어떻게 하는 것일까? 크게 깃은 Local, HTTP, SSH, Git 4가지 종류의 전송 방식을 지원한다.
-
Local
- 로컬 컴퓨터에 원격 저장소를 생성하는 것을 의미한다. 이 방식은 자신의 컴퓨터를 Network File System 등 서버로 이용할 때 편리하다.
- 로컬 저장소를 서버로 이용할 때는 폴더 경로만 입력하면 된다.
- 로컬은 간단하게 원격 서버를 구축할 수 있으며 빠른 동작이 가능하지만 본인 컴퓨터가 뽀각되는 순간 모든게 날라간다.
git remote add 원격저장소별명 폴더경로 -
HTTP
- GitHub, GitBucket 같은 호스팅 서비스와 깃에서 지원하는 프로토콜로 웹 상에서 자주 사용되는 프로토콜이다.
- 이 경우 서버에 접속하려면 로그인 절차를 거쳐야 한다. 하지만 익명으로도 처리할 수 있으며 계정을 이용해서 처리할 수 있다.
-
SSH
- 깃에서 권장하는 프로토콜로 높은 수준의 보안 통신으로 저리한다.
- SSH 프로토콜을 사용하려면 주소 앞에 ‘ssh://계정@주소’ 처럼 프로토콜 타입을 지정해야 한다.
- SSH 접속을 할 때는 인증서를 만들어서 사용한다. 인증서를 만들어서 접속하면 별도의 회원 로그인 절차를 거치지 않아도 된다.
- 인증서는 공개키와 개인키로 구분되는데 공개키는 서버에, 개인키는 로컬에 저장한다.
- HTTP와 달리 익명으로 접속할 수 없다.
-
Git
- 깃의 데몬 서비스를 위한 전용 프로토콜 방식이다.
- SSH와 유사하나 인증 시스템이 없어 보안은 취약할 수 있다.
- 실제로 이 프로토콜은 자주 사용되지 않는다.
이렇게 4가지 방식이 사용된다는 것을 알고 다음 라인들을 살펴보자
우리는 우선 HTTP 방식을 사용한다.
git remote add 원격저장소 별명 원격저장소URL위 코드는 원격 저장소와 연결을 위한 커멘드이다.
원격 저장소 별칭과 URL을 입력하면서 연결을 추가할 수 있다.
잘 연결이 되었는지는 아래 명령어를 통해서 확인할 수 있으며 -v 는 옵션으로 주소와 별명을 모두 알아볼 수 있다.
git remote -v
확인을 해보니 잘 연결된 되었는데 fetch, push가 나뉘어 있다.
이게 무엇을 말하는 것일까?
fetch는 서버에서 가지고 오는 동작, push는 서버로 전송하는 동작을 말한다.
실제로 두 동작을 해보기로 하자.
4. push를 해보자!
push는 앞서 언급했던 것 처럼 원격 저장소로 commit된 파일들을 업로드 하는 동작이다.
동작 커멘드는 아래와 같다.
git push 원격저장소별칭 브랜치이름별칭 이름을 가지는 서버의 master 브랜치에 현재 브랜치를 업로드한는 의미로 브랜치가 뭔지는 차후에 알아보도록 한다.
우리가 아직 하지 못한 커멘드인 push 커멘드(GitHub 레포지토리 화면 1방법의 마지막 라인)을 실행해보자.
동일하게 실행해도 좋고 아니면 -u 옵션을 제외해도 된다.
해당 옵션은 원격저장소별칭과 브랜치이름을 입력하는 과정을 다음부터는 생략해준다. 한마디로 해당 위치로 push를 계속 할 것이니 저장해둬 라는 의미인 것이다. 본인은 생략하고 진행해보았다.
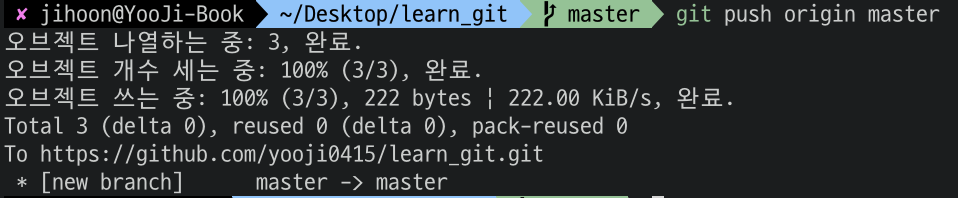
위 명령어를 통해서 우리는 origin 이라는 별명을 가지고 있는 원격 서버의 master 브랜치라는 것을 생성하고 해당 브랜치에 우리의 commit 상태와 코드를 올려준 것이다.
한 번 우리가 코드를 참고한 레포지토리 페이지를 새로고침 해보자.
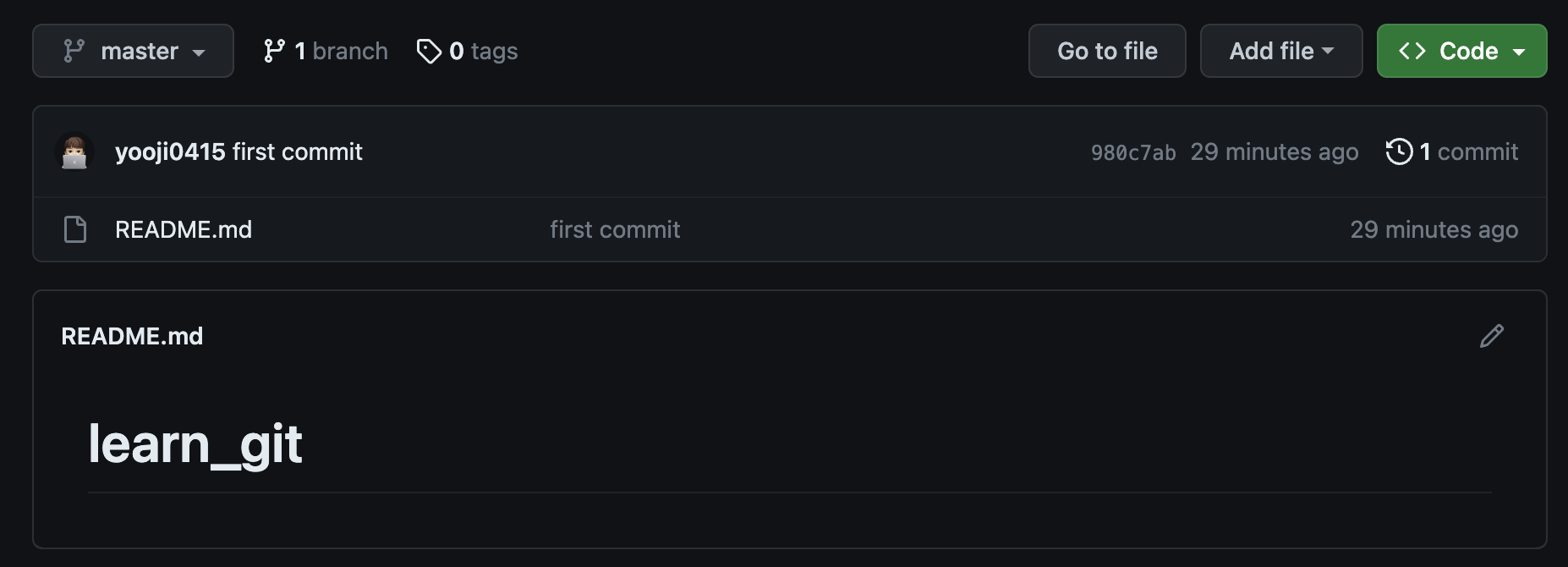
우리가 입력한 README.md가 반겨준다.
이렇게 우리는 push 기능을 간단하게 살펴보았다.
5. 원격 저장소의 파일들을 받아보자!
우리는 앞서 예시를 들어가며 왜 협업에 도움이 되는지 알아보았다. 그때 크게 두 가지가 나뉜다.
- 나는 기존 코드가 일부 있고 새로운 버전을 받고 싶은 경우 (기존 개발자)
- 기존 코드가 없고 현 시점 최신 버전을 내려 받고 싶은 경우 (신입)
이 두 케이스에 어울리는 명령어들이 다르다.
신입의 경우 clone, 기존 개발자의 경우에는 pull, fetch 등이 어울린다.
두 경우 모두 알아보자.
clone
clone은 복제를 말한다. 말 그대로 기존 저장소를 이용해서 새로운 저장소를 만드는 방법 중 하나이다.
clone 명령어는 초기화 init 명령어 외의 서버 접속에 필요한 추가 설정을 자동으로 수행해준다.
이 명령어를 하면 서버 연결 설정, 서버 안에 있는 모든 커밋 코드 이력 내려받기 순서로 작업이 진행된다.
아래 코드를 사용해서 한번 도전해보자.
mkdir clone_test
cd clone_test
git clone 레포지토리https주소.git .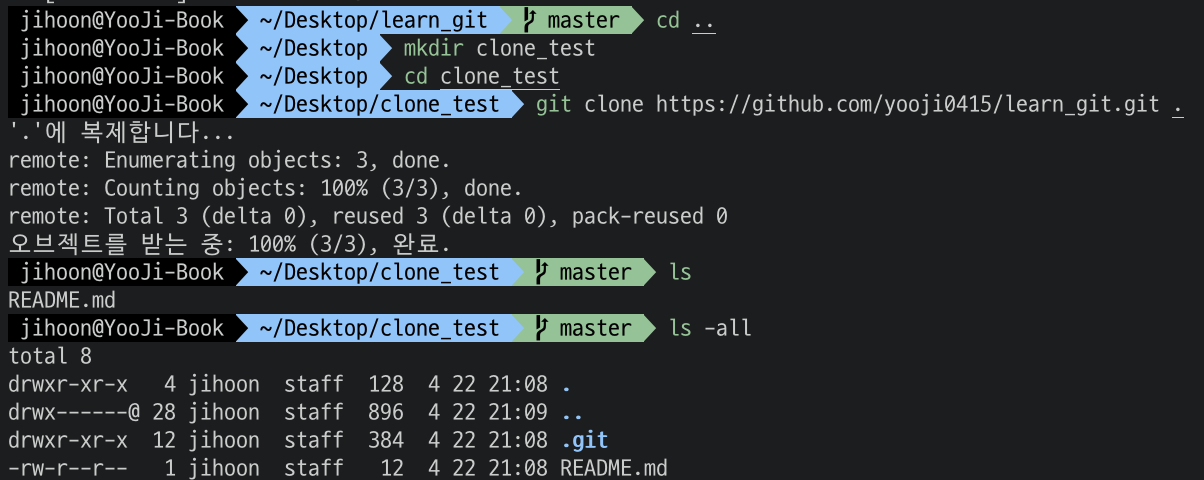
성공적으로 보인다. 우리가 작성한 README.md 파일 일 것이다. 또한 .git 폴더도 보이는 것을 확인할 수 있다.

또한 git remote 명령어를 통해서 원격 저장소도 연결된 것도 확인할 수 있다.
pull & fetch
pull의 경우 원격 저장소의 갱신된 내용을 추가로 내려받기 위한 명령이다.
pull 명령어를 통해 로컬 저장소가 원격 저장소보다 버전이 낮을 경우 해당 내용들을 내려받을 수 있는 것이다.
한 번 테스트를 해보자
우선 처음 생성한 폴더에 새로운 파일을 추가하고 해당 파일을 commit 해보자.
완료했으면 이전처럼 push 를 통해 원격 저장소에 commit 정보를 올릴 수 있다.
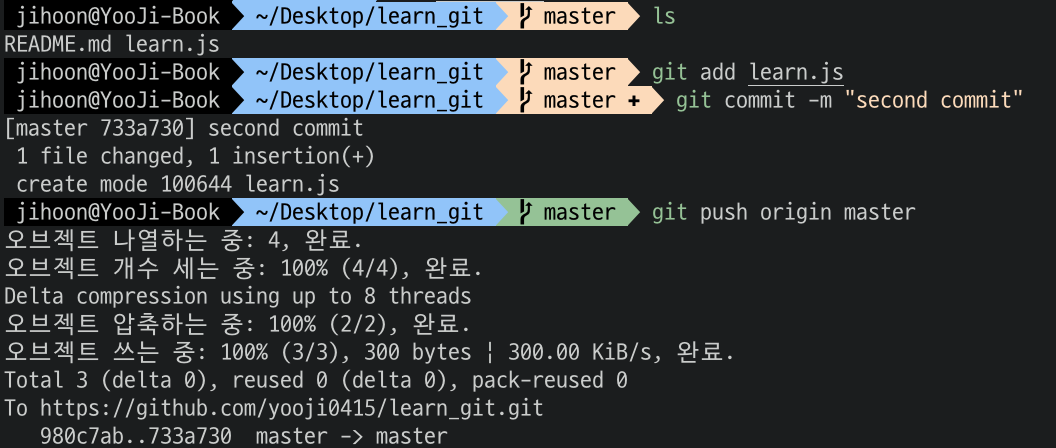
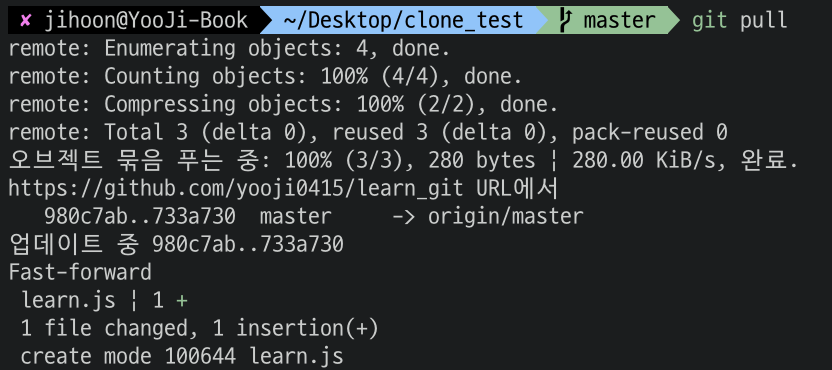
이제는 clone 한 저장소로 이동해서 git pull 명령어를 진행해보자.
명령어 진행 전 후로 log 명령도 실행해보면 차이를 확인할 수 있다.

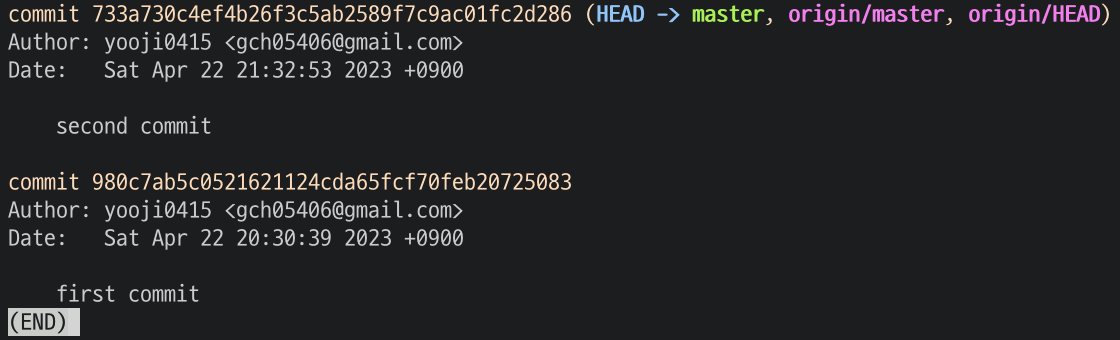
pull 명령을 하기 전에는 기존의 commit 1개만 있는 것을 볼 수 있다.
이후 pull 명령을 하게 되면 다음과 같이 learn.js를 생성되고 commit 또한 생성되는 것을 볼 수 있다.
이처럼 pull은 서버 저장소와 로컬 저장소간 commit을 반영할 수 있는 명령어이다.
그러면 fetch는 무엇일까?
먼저 둘의 차이를 설명하고 시작하면 두 방법의 차이는 병합(merge)을 자동처리하는가의 차이이다.
pull의 경우 서버 저장소에 현 시점 commit보다 더 최신 commit 정보가 있을 때 내려받는 명령이다.
이 때 내려받은 commit 정보는 스테이지 영역이 아닌 서버 저장소를 위한 전용 임시 브랜치에 내려받는다. 이후 내려받은 최신 commit들과 현재 브랜치를 자동으로 합쳐준다.(병합)
자동으로 해주고 편한데 그러면 fetch라는 명령어는 왜 하는 것일까?
여러 사람과 개발을 하다보면 지금 본인이 작성하고 있는 부분과 서버에 새롭게 추가된 내용이 다른 경우가 있을 수 있다. 이러한 상황을 충돌이라고 하는데 이런 충돌이 있는 경우에는 자동 병합이 되지 않는다.
이런 경우에 fetch를 통해서 수동으로 내려받는 방식이 있다.
이 병합과 충돌이라는 개념은 브랜치 개념을 알고 난 이후에 더 살펴볼 내용이니 일단 이 차이를 안 상태로 테스트를 해보자.
git fetch 원격저장소URL위와 같은 방법으로 사용할 수 있다. 한번 자동 병합하지 않는다는 의미를 알아보자.
이전과 동일하게 새로운 파일을 원본 저장소에서 생성하고 서버로 올려보자
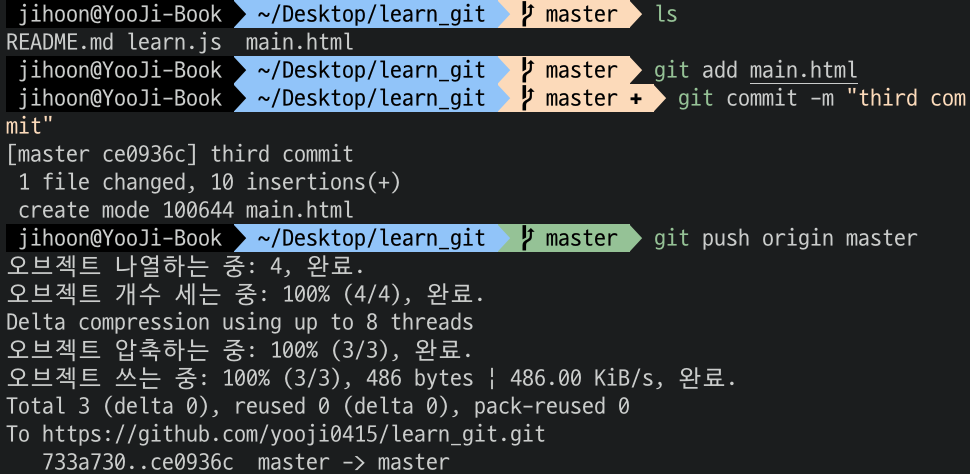
준비는 완료했다. 이제 남은 일은 fetch를 사용해보는 것이다.
fetch 원격 저장소 URL의 경우 remote -v 를 통해서 확인해봤던 것 처럼 잘 연결되어있기 때문에 바로 git fetch를 해도 무방하다. fetch를 했으면 바로 log를 찍어보자.
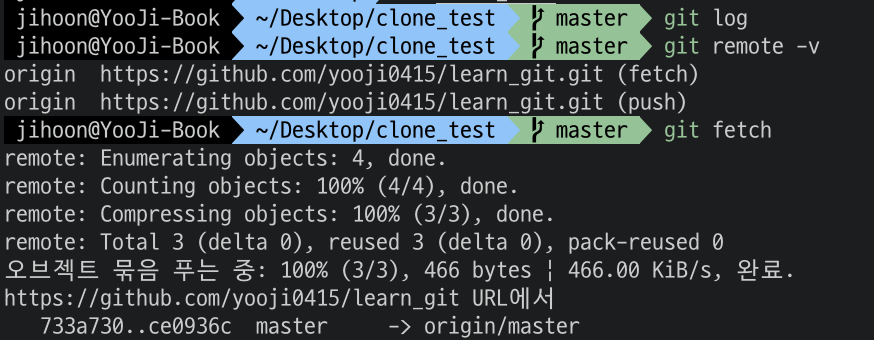
전과 후를 비교해보면 큰 차이가 없다. 뭔 일인가? 우리는 분명 내려받은 것 같은데?
하지만 차이는 있다. 기존에 있던 origin/master, origin/HEAD가 사라졌다. 이 말은 origin 원격 저장소의 master 브랜치의 최신 버전이 바뀌었다는 점을 의미한다. 이는 이전의 원본 저장소에서 push를 했기 때문이다.
그러면 우리가 받아온 것은 어디있는 것인가?
앞서 말한 것 처럼 우리가 받아온 내역들은 지금 서버 저장소를 위한 임시 브랜치에 저장되어있다.
이 임시 브랜치의 이름은 원격 저장소 이름 / 브랜치 이름 즉 우리 상황에서는 origin/master 이다.
우리는 이 브랜치에 있는 서버 저장소의 최신 내역을 병합해야 한다. 병합은 차후에 배울 것이니 이번에는 아래 명령어를 그대로 실행해본다.
git merge origin/master
드디어 우리의 새로운 파일이 생성되었다.
log도 확인해보자.
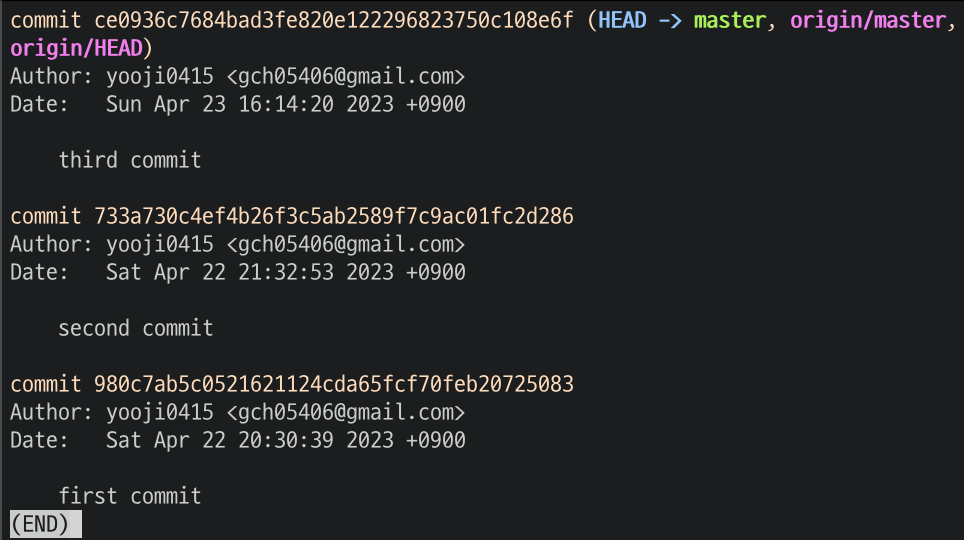
서버와 동일하게 최신 commit이 다 있는 것을 볼 수 있다.
이렇게 fetch와 pull의 차이가 있다는 정도를 알아두고 차후 브랜치와 병합 부분에서 궁금한 부분을 해소하도록 하자.
⚠️ 주의할 점은 무엇이 있을까?
크게 두 가지를 주의하면 된다. 한 번 하나씩 알아보자.
최신 상태
먼저 원격 저장소에 push하려면 자신의 로컬 저장소를 최신 상태로 유지해야한다.
즉 자신의 저장소가 원격 저장소의 commit보다 최신이여야 한다는 의미이다.
만약 누군가 내 저장소보다 먼저 commit하여 새로운 commit으로 서버를 갱신해뒀다고 가정하자.
이런 경우 내 저장소는 갱신된 서버 정보를 가지고 있지 않다.
push란 서버의 마지막 commit과 push되는 commit을 병합하는 과정이다. 이때의 내 commit은 서버의 commit보다 늦은 commit이 되기 때문에 깃은 push 동작을 거부한다.
만일 이러한 경우를 만났다면 pull 또는 fetch를 통해서 자신의 로컬 저장소를 갱신한 이후 본인의 commit을 올리면 된다.
충돌 방지
그러면 왜 깃은 최신 상태에서만 push를 허용하는 것일까?
이는 충돌을 방지하기 위해서이다. 원격 저장소의 commit을 내려받는 pull은 내려받은 commit들이 순차적이지 않으면 병합과정에서 충돌이 일어난다.
이러한 상황이 발생하지 않도록 깃은 push를 할 때 commit의 순차적 기록을 확인한다.
따라서 push 명령을 사용할 때는 충돌을 최소화하기 위해 미리 원격 저장소를 확인하는 것을 추천한다.
새로운 commit이 있는지 pull 명령어를 사용해서 지속적으로 확인하는 것도 좋다.
🙇🏻♂️ 다음에는 무엇을?
서버 저장소라는 개념을 알아보면서 분명 브랜치, 병합이라는 단어가 이해가 가지 않았을 것이다.
이는 깃의 핵심 개념들 중 하나이니 다음 시간에 빠르게 알아보면서 이번 장에서 궁금했던 내용들을 해소할 수 있도록 빠른 시일 내에 돌아오도록 하겠다.
긴 글 읽어주신분이 계신다면 감사 표시를 하면서 물러나겠다. 총총총…